



Daten und KI in der Abwasser- / Baubranche
Während KI längst unseren Arbeitsalltag durchdringt – E-Mails schreibt, Meetings transkribiert und in Office-Tools mitdenkt – stellt sich die Frage: Wo bleibt die künstliche Intelligenz in der Baubranche? Es zeigt sich: Ohne standardisierte, strukturierte Daten bleiben selbst die leistungsfähigsten Sprachmodelle blind. Kein Bauprojekt gleicht dem anderen, viele Datenquellen sind unübersichtlich, Schnittstellen fehlen. Unser Ansatz fokussiert auf diesen Punkt: Wir denken KI von den Daten her – und entwickeln praxisnahe Betaversionen, die zur Mitgestaltung einladen. Damit aus Möglichkeiten reale Werkzeuge werden.
Viele Startups versprechen uns das Blaue vom Himmel und entwickeln eigene sogenannte User Interfaces (UI, Benutzeroberflächen), die im Hintergrund aber immer noch zu hundert Prozent auf einem der grossen Modelle basieren und im Arbeitsalltag dann doch nicht das Gelbe vom Ei sind. In der Wissenschaft will man vor allem zwei Dinge: Faktentreue und Reproduzierbarkeit. In der Geschäftswelt ist Letzteres oftmals kaum zu erreichen. Kein Projekt ist genau gleich. Da sind bestehende Bauten, die integriert werden müssen, verschiedene normative Anforderungen, die es zu erfüllen gilt, oder einfach die spezifischen Wünsche der Bauherrschaft.
Bei den beiden Aufgaben versagen die Sprachmodelle oft nach wie vor. Zum einen tendieren LLMs (Large Language Models) zum sogenannten Halluzinieren, also der Erfindung von Fakten und zum anderen sehen die Outputs oftmals anders aus, wenn man ein zweites Mal fragt (wenn man die Anfrage wiederholt). Zwar ist Letzteres bewusst so einprogrammiert, eignet sich aber für die Erstellung eines Berichts eher weniger. Ein weiterer Faktor ist zudem, dass sich diese Modelle ganz selten selber hinterfragen und auch von selbst äusserst ungerne Fehler zugeben.
Technisch gesehen lassen sich die Probleme beheben – unter anderem mithilfe von RAG (Retrieval-Augmented Generation). Diese Technik ermöglicht es, beispielsweise firmeninternes Wissen gezielt einem LLM bereitzustellen, sodass Anfragen zu Fakten oder unternehmensspezifischem Wissen deutlich präziser beantwortet werden können. Die einfachste Lösung dabei wäre, einfach alle PDFs, Word-Dokumente, Excel etc., die auf den Firmenservern liegen, dem RAG zu füttern. Das führt jedoch selten zu einem vielversprechenden Ergebnis. Denn was für uns Menschen nach geordneten Daten aussieht, ist für einen Computer ein absoluter Albtraum. Es stellen sich Fragen wie: Was macht man mit Bildern in den Dokumenten? Wie trennen wir lange Dokumente auf? Was sind überhaupt relevante Informationen? Wie formulieren wir ein Problem, damit es ein Computer versteht?
Wenn man diese Probleme auf den Bausektor herunterbricht, werden sie noch deutlicher. Die grossen Sprachmodelle sind auf hochstrukturierte und qualitativ hochwertige Daten angewiesen. Die Daten müssen in Formate umgewandelt werden, die von Computern verarbeitet werden können. Mit solchen standardisierten Daten tut sich die Baubranche noch schwer. So sieht beispielsweise jedes BIM-Modell (Building Information Modeling) in jedem Unternehmen anders aus. Nicht per se das visuelle Erscheinungsbild (natürlich auch), sondern wie die Daten aufbereitet sind. Der IFC-Standard (Industry Foundation Classes) versucht hier seit Jahren Abhilfe zu schaffen, aber grosse Firmen wehrten sich lange heftig dagegen und IFC ist hier nur ein Beispiel aus vielen.
Der Bund arbeitet zunehmend an einer digitalen Strategie, beispielsweise die map.geo-Schnittstelle oder die Meteodaten. Solche Schnittstellen zwingen die Beteiligten, Daten zu standardisieren. Die Strukturen in den Datenbanken sind vorgegeben und die Daten sind immer gleich aufgebaut. Eine solche Transformation braucht aber ihre Zeit. Der Mensch ist ein träges Wesen und wenn er plötzlich mehr und genauere Daten abfüllen muss, sträubt man sich gerne. Wir haben dieses Problem erkannt resp. am «eigenen Leib» mehrmals erfahren und unsere Lehren gezogen …
Wir setzen auf Standardisierung und Datenbanken, dann erst auf die KI.
Alle Daten sollen zentral an einem Ort gespeichert sein und in Sekundenbruchteilen durchsucht werden können. Der Computer muss dabei genau verstehen können, was ein solcher Datensatz bedeutet. Wir betrachten wo möglich nicht nur ein einzelnes Projekt als Datenquelle, sondern alle Projekte gleichzeitig. Dadurch können Daten einfacher ausgewertet und Prozesse sinnvoll automatisiert werden.
Wir möchten Werkzeuge zeigen, die mit genau diesem Grundgedanken entwickelt worden sind – auch wenn diese noch nicht «fertige Produkte» sind. Wir möchten mit anwendbaren Betaversionen dazu anregen, sich bereits in der Entwicklungsphase weiterführende Gedanken zu machen und immer weiter zu verbessern. Gerne nehmen wir Rückmeldungen und konstruktive Kritik entgegen und setzen Vorschläge in die Tat um.


Tools
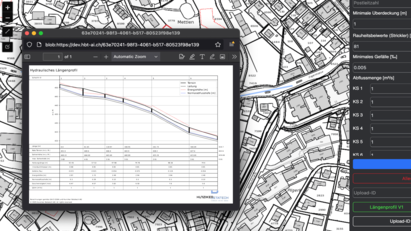

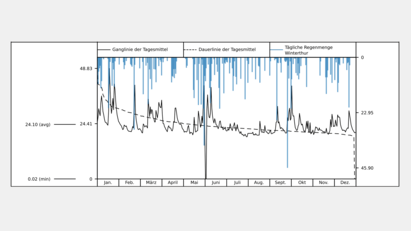


KI-partner
Wir sind sehr gut mit der Schweizer Hochschullandschaft und den Fachverbänden vernetzt.
Unsere wichtigsten Partner sind:


